RoRD 毕业设计总结:面向 IC 版图的结构感知局部特征匹配
这篇文章整理自我的毕业设计,主题仍然围绕 RoRD 在 IC 版图模式匹配中的落地。相比前几篇阶段性报告,这一次更像一个收束版本:问题定义、方法设计、实验协议、baseline 对比和工程边界都已经放到同一个框架里重新梳理。
目标是在不显式枚举模板旋转与镜像版本的前提下,从大尺寸 IC 版图中检索出所有与模板结构等价的目标实例。最终方案把版图结构先验编码进输入表示与局部特征学习,再用大图滑窗、RANSAC 和迭代屏蔽完成多实例搜索。
为什么这个问题值得做
IC 版图模式匹配的任务,是在大尺寸 layout 中定位与给定 template 相同或结构等价的局部单元。它可以服务于设计复用验证、相似结构检索、异常结构排查、IP 保护、版图审查等流程。
传统流程中一个很直接的问题是:目标实例经常以旋转、镜像和平移形式重复出现。如果把 0、90、180、270 度旋转和镜像都考虑进去,系统往往要对同一模板构造近似 8 种状态并分别搜索。这样做可以覆盖问题,但也会带来更高计算开销和更脆弱的工程流程。
从视觉建模角度看,IC 版图又不同于自然图像。它通常是二值化、弱纹理、强几何约束、高重复密度的数据,语义更多来自线段、折线、拐角、端点、重复单元和拓扑关系。因此,直接迁移自然图像中的局部特征方法并不理想。
本文真正想回答的问题是:
能否让模型直接学习旋转与镜像条件下稳定的版图结构表示,并把这种表示用于大图、多实例检索?
方法总览
整体流程可以分成两部分:模型学习“什么位置值得匹配、如何描述这些位置”,检索流程负责“如何在超大 layout 中高覆盖率地找到所有实例”。
系统输入为模板图像 和大版图图像 ,输出匹配框集合:
其中, 表示第 个匹配框, 表示置信度, 表示几何解释信息,例如尺度、旋转或镜像属性。
四通道结构表示
为了让模型更直接看到版图里的结构语义,最终方案没有只使用单通道二值图,而是构造四通道输入:
| 通道 | 作用 |
|---|---|
| 原始二值通道 | 保留整体轮廓 |
| 骨架通道 | 保留主干结构与连通关系 |
| 角点通道 | 强化局部转折信息 |
| 端点通道 | 强化结构起止位置 |

这个设计的核心动机很简单:版图里最有判别力的东西不是纹理,而是拐角、端点、骨架和它们之间的组合关系。四通道表示相当于把这些结构先验显式交给网络。
联合检测与描述子学习
模型采用共享骨干网络,并在其上构建两个分支:
- 检测分支输出关键点响应图,用来判断哪些位置值得参与匹配。
- 描述子分支输出局部特征向量,用来描述这些位置的结构语义。
训练阶段使用自监督几何一致性:从版图中裁剪 patch,对其施加旋转、镜像、尺度和光度扰动,同时保留已知变换关系。这样不需要人工关键点标注,也能构造变换前后的正负样本关系。
总损失可以写成:
检测损失进一步强调两件事:
| 子项 | 解决的问题 |
|---|---|
| 同一个结构在旋转、镜像或平移后是否仍能在对应位置被检测到 | |
| 检测响应是否集中在拐角、端点、交汇点等真正有匹配价值的位置 |
描述子损失则把同源结构拉近、异源结构拉远:
版图里的负样本并不总是“看起来完全不同”的区域,很多时候是局部结构很像但几何上不对应的重复单元。因此,描述子学习必须承担区分重复结构、压制伪对应的任务。
模型与推理配置
主实验采用 VGG16 + FPN 结构:
| 配置项 | 设置 |
|---|---|
| 输入 | 4 通道结构图 |
| Backbone | VGG16,首层改为 4 通道输入 |
| FPN 层级 | P2 / P3 / P4 |
| FPN 输出通道 | 256 |
| 描述子维度 | 128 |
| 注意力模块 | 当前实验关闭 |
训练配置如下:
| 项目 | 设置 |
|---|---|
| Patch 尺寸 | |
| Batch size | 8 |
| 学习率 | |
| Epoch | 50 |
| 尺度扰动 | |
| 数据增强 | 亮度/对比度扰动、高斯噪声 |
| 训练数据 | ICCAD2019 真实样本 |
推理阶段对大图采用滑动窗口特征提取,再统一映射回全局坐标:
| 项目 | 设置 |
|---|---|
| 窗口大小 | 1024 |
| 步长 | 768 |
| 匹配尺度 | |
| 关键点响应阈值 | 0.5 |
| RANSAC 重投影误差阈值 | 5.0 像素 |
| 最小内点数阈值 | 15 |
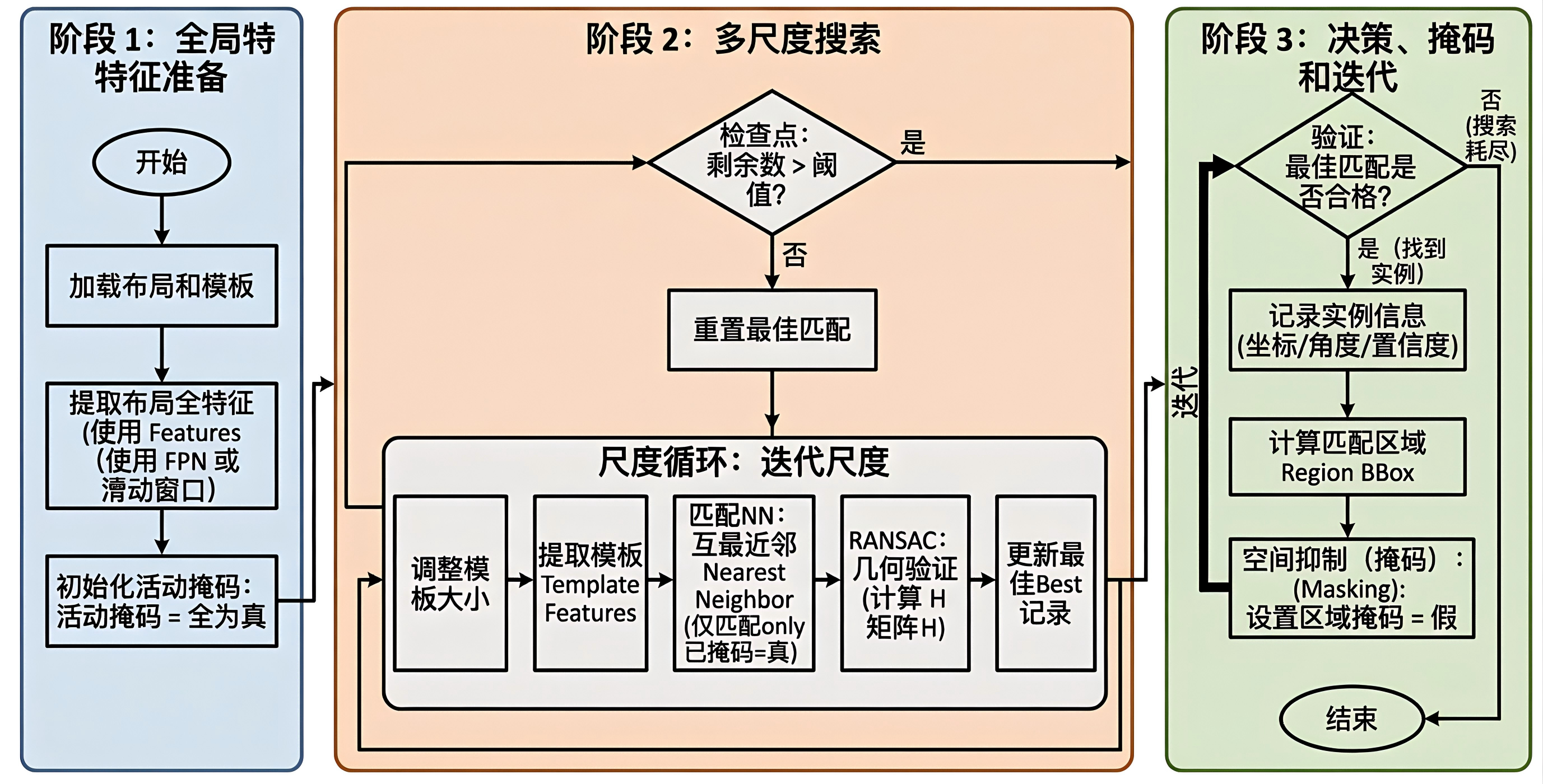
大图多实例检索流程
检索流程并不追求一次性找到全局最优解,而是采用“验证一个实例、屏蔽一个实例、继续搜索剩余实例”的迭代方式:
1. 提取模板特征
2. 通过滑动窗口提取整张 layout 的关键点与描述子
3. 在未屏蔽区域中选择候选关键点
4. 与模板描述子建立初始匹配
5. 使用 RANSAC 做几何验证
6. 若内点数超过阈值,则投影模板框并记录结果
7. 屏蔽已匹配区域,继续搜索下一个实例这种设计比较适合高重复密度的版图场景。候选点保留得更充分,真正的筛选压力后移到几何验证阶段,从而降低早期阈值误杀目标实例的风险。
实验数据与评价方式
测试集由一张 阵列规模的大尺寸版图构成,内部包含给定模板的原始状态、离散旋转状态及其镜像状态,共 9 个真值目标。


评价指标包括:
| 指标 | 含义 |
|---|---|
| Center-hit Precision | 预测框中心落入真实框的比例 |
| Center-hit Recall | 被成功命中的真实目标比例 |
| IoU Recall@0.1 | IoU 大于 0.1 的真实目标覆盖率 |
| Layout Feature Time | 大图特征提取耗时 |
| Match Pipeline Time | 匹配与几何验证耗时 |
这个测试集适合验证“无需模板状态枚举也能覆盖旋转、镜像和多实例目标”这一核心假设,但它仍然是规模有限、分布相对可控的构造场景,不能直接等价为对所有工业版图的充分泛化证明。
主方法结果
在当前测试集上,主方法覆盖全部 9 个目标:
| 方法 | 预测数量 | Center Precision | Center Recall | IoU Recall@0.1 |
|---|---|---|---|---|
| 本文方法 | 9 | 1.0 | 1.0 | 1.0 |
关键点响应也符合预期:模型倾向于在拐角、端点和复杂结构交汇处产生响应,而不是平均铺满背景区域。


匹配流程中的几个阶段如下:




从 profile 看,当前系统的主要耗时集中在大图特征提取:
| 阶段 | 耗时 |
|---|---|
| Layout 特征提取 | 25563.531 ms |
| 匹配阶段 | 1256.519 ms |
这说明最值得继续优化的地方不是 RANSAC 或匹配循环,而是首次大图前向特征提取。
Baseline 对比
为了比较不同特征表示对版图任务的适应性,实验加入了 ORB、SIFT、SuperPoint 和 SuperPoint + LightGlue。为了让它们能参与同一个任务,baseline 也补充了滑动窗口、区域屏蔽和迭代搜索外壳。
| 方法 | 预测数量 | Center Precision | Center Recall | IoU Recall@0.1 |
|---|---|---|---|---|
| 本文方法 | 9 | 1.0 | 1.0 | 1.0 |
| ORB | 5 | 1.0 | 0.5556 | 0.5556 |
| SIFT | 6 | 0.8333 | 0.5556 | 0.5556 |
| SuperPoint | 0 | 0.0 | 0.0 | 0.0 |
| SuperPoint + LightGlue | 12 | 0.0 | 0.0 | 0.0 |




耗时对比如下:
| 方法 | 主要流程耗时 |
|---|---|
| 本文方法:Layout 特征提取 | 25563.531 ms |
| 本文方法:Match Pipeline | 1256.519 ms |
| ORB:Sliding Window + Iteration | 9185.479 ms |
| SIFT:Sliding Window + Iteration | 56827.718 ms |
| SuperPoint:Sliding Window + Iteration | 2440.836 ms |
这组结果可以读出几个现象:
- ORB 在规则角点较多的二值版图上仍有一定有效性,但对镜像目标与重复结构的全局区分能力不足。
- SIFT 能命中部分目标,但在弱纹理版图中没有体现出经典自然图像场景下的优势,并且耗时更高。
- SuperPoint 的自然图像预训练分布与 IC 版图差异较大,在当前设置下没有形成有效候选。
- LightGlue 依赖前端特征质量;如果输入匹配对本身不适合版图结构,更强的匹配器也难以恢复正确几何定位。
- 主方法的优势不在于所有阶段都最快,而在于任务完成度、目标覆盖率、旋转镜像适应性和减少显式枚举依赖上的综合表现更稳。
方法边界
当前方案并不是已经解决了所有版图检索问题。它更适合局部结构清晰、拓扑关系明确、复用单元明显的场景。以下情况仍需要继续验证:
- 跨工艺节点、跨设计风格、跨分辨率的真实工业版图。
- 极小模板,因为可供建模的局部结构太少。
- 超高重复结构,因为相似候选之间竞争会更强。
- 超出当前多尺度范围的尺度差异。
- 更严格的旋转、镜像不变性消融实验。
从工程定位看,这个版本更适合作为离线版图分析、批量结构检索或辅助审查模块,而不是强实时交互工具。大图滑动窗口特征提取仍然是当前最大的时间瓶颈。
下一步
毕业设计给这个方向建立了一个可运行的闭环:结构表示、局部特征学习、大图搜索、几何验证、多实例迭代和 baseline 比较都已经串起来了。后续最值得继续推进的方向包括:
- 加速大图滑动窗口特征提取,减少重叠窗口的重复前向计算。
- 扩充真实测试集,覆盖更多工艺节点、设计风格和版图密度。
- 做更系统的消融实验,验证四通道输入、结构损失、FPN 和迭代屏蔽各自的贡献。
- 引入更贴近工业使用习惯的传统版图检索方法作为 baseline。
- 探索从光栅化输入走向矢量版图输入,在保留结构容错能力的同时降低大图卷积成本。
总体而言,这篇毕业设计证明了一件对我很重要的事情:RoRD 这条线不只是“把自然图像匹配方法搬到版图上”,而是需要把版图的结构先验、几何约束和大图检索流程放在一起重新设计。也正是在这个意义上,它仍然是一个值得继续往下挖的方向。
正在加载评论...