RoRD Graduation Project: Structure-Aware Local Feature Matching for IC Layouts
Apr 29, 2026
RoRD Graduation Project: Structure-Aware Local Feature Matching for IC Layouts
This post summarizes my graduation project on applying RoRD-inspired local feature matching to IC layout pattern retrieval. Compared with the earlier progress reports, this version is more complete: it connects the problem definition, method design, experimental protocol, baseline comparison, and engineering limitations in one place.
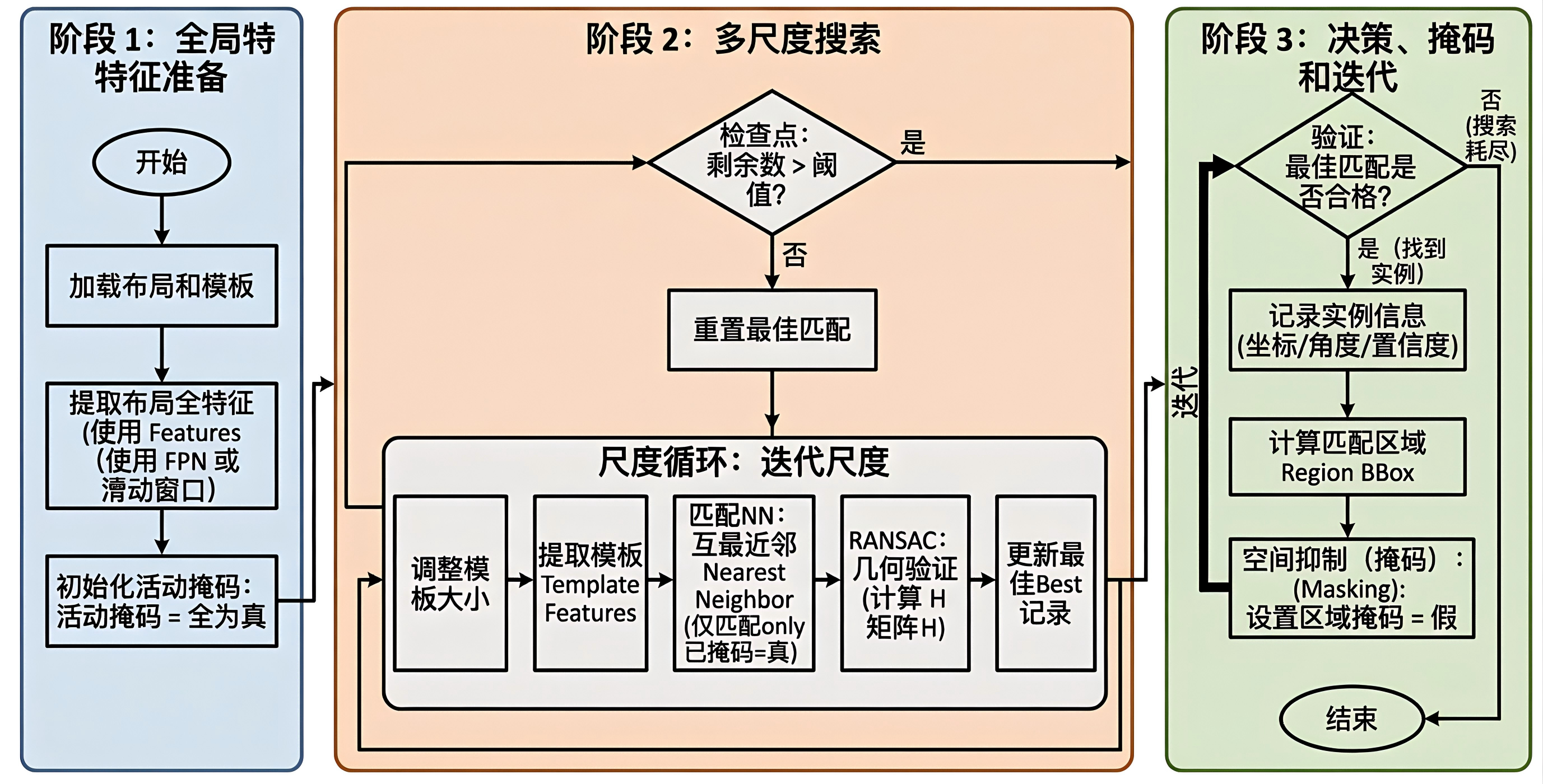
The goal is to retrieve all template-equivalent instances from a large IC layout without explicitly enumerating rotated and mirrored template variants. The final pipeline encodes layout structure into both the input representation and the learned local features, then combines sliding-window layout extraction, RANSAC verification, region masking, and iterative multi-instance search.
Motivation
IC layout pattern matching aims to localize structures in a large layout that are identical or structurally equivalent to a given template. It is useful for design reuse validation, similar-structure retrieval, anomaly inspection, IP protection, and layout review.
A direct difficulty is geometric variation. Target instances often appear under rotation, reflection, and translation. If four rotations and mirroring are considered, a conventional pipeline may need to search nearly eight transformed versions of the same template, which increases computation and complicates the retrieval process.
IC layouts also differ sharply from natural images. They are usually binarized, weakly textured, highly geometric, and densely repetitive. Their semantics are expressed more by line segments, corners, endpoints, repeated cells, and topology than by texture. This makes direct transfer of natural-image local features unreliable.
The central question of this work is:
Can a model learn a stable structural representation under rotation and reflection, and can that representation be used for large-layout, multi-instance retrieval?
Pipeline
The method separates two responsibilities. The model learns which locations are worth matching and how to describe them; the retrieval pipeline decides how to find all instances across a large layout.
Given a template image and a large layout image , the system outputs a set of matched boxes:
Here, is the matched box, is the confidence score, and records geometric information such as scale, rotation, or reflection.
Four-Channel Structural Input
Instead of using only a single binary layout image, the method builds a four-channel representation:
| Channel | Purpose |
|---|---|
| Raw binary layout | Preserves the overall shape |
| Skeleton | Encodes connectivity and main structure |
| Corners | Highlights local turning points |
| Endpoints | Highlights structure boundaries |

The key idea is that the most discriminative cues in IC layouts are not textures, but corners, endpoints, skeletons, and their combinations. The four-channel input makes these structural priors directly visible to the network.
Joint Keypoint and Descriptor Learning
The model uses a shared backbone with two heads:
- A detection head predicts a keypoint response map.
- A descriptor head predicts local descriptors for matching.
Training uses self-supervised geometric consistency. Layout patches are transformed by rotation, reflection, scale perturbation, and photometric noise while the transformation relation is kept known. This provides positive and negative pairs without manual keypoint labels.
The total loss is:
The detection loss emphasizes both repeatability and structural usefulness:
| Term | Role |
|---|---|
| Ensures the same structure remains detectable after rotation, reflection, or translation | |
| Encourages responses around corners, endpoints, junctions, and other useful structural regions |
The descriptor loss pulls corresponding structures together and pushes non-corresponding structures apart:
In layout images, negative samples are often not visually unrelated regions. They may be locally similar but geometrically incorrect repeated structures. This makes descriptor learning especially important for suppressing false correspondences.
Model and Inference Settings
The main experiment uses a VGG16 + FPN architecture:
| Item | Setting |
|---|---|
| Input | Four-channel structural image |
| Backbone | VGG16 with a four-channel first convolution |
| FPN levels | P2 / P3 / P4 |
| FPN channels | 256 |
| Descriptor dimension | 128 |
| Attention module | Disabled in the main experiment |
Training settings:
| Item | Setting |
|---|---|
| Patch size | |
| Batch size | 8 |
| Learning rate | |
| Epochs | 50 |
| Scale jitter | |
| Augmentation | Brightness/contrast perturbation and Gaussian noise |
| Training data | Real ICCAD2019 samples |
Inference settings:
| Item | Setting |
|---|---|
| Window size | 1024 |
| Stride | 768 |
| Matching scales | |
| Keypoint threshold | 0.5 |
| RANSAC reprojection threshold | 5.0 pixels |
| Minimum inlier threshold | 15 |
Large-Layout Multi-Instance Retrieval
The retrieval pipeline does not try to solve the whole image in one global step. Instead, it verifies one instance, masks it, and continues searching:
1. Extract template features.
2. Extract layout features with sliding windows.
3. Select candidate keypoints from unmasked regions.
4. Match template descriptors against layout descriptors.
5. Run RANSAC for geometric verification.
6. If the inlier count passes the threshold, project and record the template box.
7. Mask the matched region and continue searching.This is well suited to densely repetitive layout scenes. Candidate keypoints are kept with high coverage, while RANSAC handles the main filtering burden later in the pipeline.
Dataset and Metrics
The test layout is an composed layout containing nine ground-truth targets, including the original template state, discrete rotations, and mirrored variants.


Metrics:
| Metric | Meaning |
|---|---|
| Center-hit Precision | Fraction of predicted boxes whose centers fall inside ground-truth boxes |
| Center-hit Recall | Fraction of ground-truth targets hit by predicted centers |
| IoU Recall@0.1 | Fraction of ground-truth targets covered by predictions with IoU above 0.1 |
| Layout Feature Time | Time spent extracting large-layout features |
| Match Pipeline Time | Time spent on matching and geometric verification |
This dataset is useful for testing whether the method can cover rotated, mirrored, and multi-instance targets without explicit template-state enumeration. It is still a limited and controlled benchmark, so it should not be read as a full generalization proof for all industrial layout scenarios.
Main Results
On the current benchmark, the proposed method retrieves all nine targets:
| Method | Predictions | Center Precision | Center Recall | IoU Recall@0.1 |
|---|---|---|---|---|
| Proposed method | 9 | 1.0 | 1.0 | 1.0 |
The keypoint responses also match the design intention: they concentrate around corners, endpoints, and complex structural junctions instead of spreading uniformly over background regions.


Intermediate matching results:




Profiling shows that the main bottleneck is large-layout feature extraction:
| Stage | Time |
|---|---|
| Layout feature extraction | 25563.531 ms |
| Matching stage | 1256.519 ms |
This suggests that the next major optimization target is not RANSAC or the matching loop, but the first forward pass over the large layout.
Baseline Comparison
The experiment compares the method with ORB, SIFT, SuperPoint, and SuperPoint + LightGlue. To make the task comparable, the baselines are wrapped with the same sliding-window, masking, and iterative-search scaffold.
| Method | Predictions | Center Precision | Center Recall | IoU Recall@0.1 |
|---|---|---|---|---|
| Proposed method | 9 | 1.0 | 1.0 | 1.0 |
| ORB | 5 | 1.0 | 0.5556 | 0.5556 |
| SIFT | 6 | 0.8333 | 0.5556 | 0.5556 |
| SuperPoint | 0 | 0.0 | 0.0 | 0.0 |
| SuperPoint + LightGlue | 12 | 0.0 | 0.0 | 0.0 |




Timing comparison:
| Method | Main pipeline time |
|---|---|
| Proposed method: layout feature extraction | 25563.531 ms |
| Proposed method: match pipeline | 1256.519 ms |
| ORB: sliding window + iteration | 9185.479 ms |
| SIFT: sliding window + iteration | 56827.718 ms |
| SuperPoint: sliding window + iteration | 2440.836 ms |
Several observations stand out:
- ORB remains partially effective on binary Manhattan-style layouts, but it struggles with mirrored targets and dense repeated structures.
- SIFT hits part of the targets, but it does not show its usual natural-image advantage in this weak-texture setting and is slower.
- SuperPoint, pretrained mainly for natural images, does not adapt well to this layout distribution under the current settings.
- LightGlue depends on the quality of the input correspondences; a stronger matcher cannot recover correct geometry if the front-end features are not layout-aware.
- The proposed method is not the fastest in every stage, but it gives a stronger overall tradeoff in task completion, target coverage, rotation/reflection adaptation, and reduced template enumeration.
Limitations
This work does not solve every layout retrieval problem. It is best suited for layouts with clear local structures, explicit topology, and reusable cells. The following cases still need more validation:
- Real industrial layouts across process nodes, design styles, and resolutions.
- Very small templates with too few structural cues.
- Extremely repetitive regions with many competing similar candidates.
- Scale gaps beyond the current multi-scale search range.
- More rigorous ablation studies on rotation and reflection invariance.
From an engineering perspective, the current version is better positioned as an offline layout analysis, batch retrieval, or review-assistance module than as a low-latency interactive tool. Sliding-window feature extraction remains the dominant bottleneck.
Next Steps
The graduation project establishes a complete working loop: structural representation, local feature learning, large-layout retrieval, geometric verification, iterative multi-instance search, and baseline comparison. The next useful directions are:
- Accelerate sliding-window layout feature extraction and reduce redundant computation across overlapping windows.
- Expand the real test set across more process nodes, design styles, and layout densities.
- Add systematic ablations for the four-channel input, structural loss, FPN, and iterative masking.
- Compare against more industrially relevant traditional layout retrieval methods.
- Explore vector-layout inputs to reduce rasterization and convolution cost while preserving structural tolerance.
Overall, this project shows that RoRD-style layout recognition is not just a matter of moving natural-image matching into IC layouts. The structural priors, geometric constraints, and large-layout retrieval pipeline have to be designed together. That is why this direction still feels worth digging into.
Loading comments...